我家那些真能用的工人
一句话:这篇文章分享我在家用硬件上部署的高性价比大语言模型解决方案及实际使用体验。
写在前面
如今,语言模型的规模已能适配单张 NVIDIA RTX 3090 (24G VRAM) 的硬件配置,且开源模型的部署成本大幅降低。对于普通用户而言,这既是技术普惠的趋势,也是探索 AI 应用的绝佳契机。
我撰写这篇指南的初衷,是希望与大家分享在家中运行语言模型的一些实际经验。它并非取代商业化大模型(如需付费调用的服务),而是在特定场景中发挥独特作用——这些场景尤其注重隐私保护,例如辅助保密内容的逻辑推演与思维扩展。
本文涉及的推理配置约需 48GB 显存(双 RTX 3090 24G),和一些内存。运行三个模型。这组模型文本性能对标 DeepSeek R1,既能满足轻量级基础任务需求,也支持笔者自研软件「浮望」的全部功能。因时间精力所限,不提供更多的配置方案,仅供读者作为探索起点自行拓展研究。
如果对浮望的设计和技术实现有兴趣,可以参考我们的文档。https://flowdown.ai/
想要什么
配置这组模型最开始的动力主要是需求导向的,除此之外还有对前沿技术的兴趣。笔者希望模型能够提供:
- 不算差的文本处理能力
- 整理互联网上繁琐的信息 → 有较长的上下文处理能力
- 一些简易的图片处理能力 → 能阅读图片内容
- 能提供一些简单的代码
- 满足自研软件「浮望」的全部功能 → 对话标题生成、图片识别、工具调用
- 不慢的推理速度 → 在线等急急急 → 只能用 GPU 跑
能做什么
根据上述的需求,笔者在大约半年前探索了模型的尺寸和能力的关系,将他们划分成四个等级。此部分的内容可以直接参考,能在家庭硬件中运行的模型通常小于 70B,且需要一定程度的量化。其中,加粗部分的内容,是可以在家庭硬件中运行,且能提供实际作用的。
- 不可用级别:<7B,典型模型:llama-1B
- 简单任务可用:7B - 30B,典型模型:千问 2.5 7B
- 基础任务可用:30B-80B,典型模型:Gemma-3-27B QWQ-32B llama-3-70B
- 可用:80B+,典型模型:Command-A 110B,DeepSeek-V3,DeepSeek-R1 671B
我有什么
直接贴一个配置清单吧。
,.=:!!t3Z3z., root@LAKR-HEDT
:tt:::tt333EE3 --------------
Et:::ztt33EEE @Ee., .., OS: Windows Server 2025 Datacenter [64 bit]
;tt:::tt333EE7 ;EEEEEEttttt33# Host: ASRock Z690 Taichi Razer Edition
:Et:::zt333EEQ. SEEEEEttttt33QL Kernel: 10.0.26100.0
it::::tt333EEF @EEEEEEttttt33F Motherboard: ASRock Z690 Taichi Razer Edition
;3=*^```'*4EEV :EEEEEEttttt33@. Uptime: 9 days 11 hours 25 minutes
,.=::::it=., ` @EEEEEEtttz33QF Packages: 2 (choco)
;::::::::zt33) '4EEEtttji3P* Shell: PowerShell v5.1.26100.2161
:t::::::::tt33 :Z3z.. `` ,..g. Resolution: 1024x768
i::::::::zt33F AEEEtttt::::ztF Terminal: Windows Console
;:::::::::t33V ;EEEttttt::::t3 CPU: 13th Gen Intel(R) Core(TM) i9-13900K @ 2.995GHz
E::::::::zt33L @EEEtttt::::z3F GPU: NVIDIA GeForce RTX 3090
{3=*^```'*4E3) ;EEEtttt:::::tZ` GPU: NVIDIA GeForce RTX 3090
` :EEEEtttt::::z7 GPU: Intel(R) UHD Graphics 770
'VEzjt:;;z>*` GPU: Microsoft Remote Display Adapter
Memory: 34.8 GiB / 127.75 GiB (27%)
Disk (C:): 68 GiB / 931 GiB (7%)占用资源
参数量
参数量通常能直接反应模型的性能。更大参数量的模型通常来讲性能优于同期更小参数量的模型。
上下文
上下文通俗来讲就是模型的记忆,是推理过程中除模型能力外,对用户体验影响最大的构成。
相同资源的情况下,并非更大的参数量就一定能带来更好的体验,有时,更长的上下文更适合你的任务。
简单来说,运行 70B 的模型,可能在简单对话中能有更好的输出,但是模型很快会忘记和你都聊过什么,也无法处理网络搜索。而一个 30B 的长上下文模型,不仅可以为你提取关键信息,也能提供不错的基础对话能力。
对于 48G 显存,大约可以塞入一个 70B int4 量化的模型。但是如果使用这个参数量的模型,基本上就没有多少上下文的处理能力了。
量化
模型的量化,通俗来说可以解释为:在损失较小模型性能的情况下,大幅度压缩模型占用的显存空间。在针对量化优化的模型中,性能损失通常较小。如果一定要给出一个具体的数值,大约在 20% 以内。而未对量化优化的模型,量化会直接损坏模型。具体来说,模型会输出类似乱码的内容。例如重复的文本,无效的字符等。
在针对量化优化,或者至少不损坏模型的情况下, 主观来说:int 4 量化是目前能够接受的最小压缩。 他用 4 比特整形数表示一个 8 或 16 比特的数据单元。
后文使用 int 4 作为最小量化方案。
K/V 缓存
在模型的推理过程中需要分配足够的 K/V 缓存。K/V 缓存(Key-Value Cache)是 Transformer 模型在推理阶段用于加速自注意力机制计算的一种优化技术。
你需要知道:K/V 缓存可能会占用不小的储存空间。
预处理
预处理的学名叫做 Prefill,亦可称作 Pre Process,在一些论坛中简写为 PP。
在处理长上下文的推理过程中,预处理过程的速度是一个特别重要的指标。如果速度过慢,会导致较长的等待时间。试想一下,当你完成了网页搜索,却需要等待两分钟才能看到模型的输出,是不可接受的。很多博主购买了昂贵的硬件,却忽视了预处理和长上下文对模型体验的影响。
你需要知道:选择支持 CUDA 的设备进行推理可能可以大幅度提升预处理的速度。
如果你因这篇文章开始搭建你自己的家用推理服务器,应当在硬件选择过程中调查这一点。在针对此过程进行优化的设备上进行预处理能够提供 100 乃至 1000 倍的速度提升,对使用体验有明显的提升。
参考表
下面这张表格清晰的呈现了他们在不同的量化下分别需要的硬件资源。这里有一个网站可以完成这件事情。https://smcleod.net/vram-estimator/
| 参数量 | 上下文尺寸 | 量化方式 | 模型占用(GB) | K/V缓存(GB) | 总显存占用(GB) |
|---|---|---|---|---|---|
| 7B | 16K tokens | Q4_0 | 4.4 | 1.0 | 5.5 |
| 64K tokens | Q4_0 | 4.1 | 8.6 | ||
| 128K tokens | Q4_0 | 8.3 | 12.7 | ||
| 14B | 16K tokens | Q4_0 | 8.4 | 1.5 | 9.8 |
| 64K tokens | Q4_0 | 5.9 | 14.2 | ||
| 128K tokens | Q4_0 | 11.7 | 20.1 | ||
| 32B | 16K tokens | Q4_0 | 18.5 | 2.2 | 20.7 |
| 64K tokens | Q4_0 | 8.9 | 27.3 | ||
| 128K tokens | Q4_0 | 17.7 | 36.2 | ||
| 70B | 16K tokens | Q4_0 | 39.8 | 3.3 | 43.1 |
| 64K tokens | Q4_0 | 13.1 | |||
| 128K tokens | Q4_0 | 26.2 |
选择模型
基础模型直接决定日常使用的体验。在家庭硬件部署场景下,模型性能与资源消耗的平衡是首要考量。在硬件资源非常紧张的家用级设备上进行推理时,如果想要模型能有更好的效果,选择不多。
其次是,在小参数量的模型中,通吃所有功能的模型不存在。你需要模块化的组装不同的模型,完成不同的任务。因此,本文也会根据主次模型和视觉辅助模型的路线向你阐述。
前置条件
硬件条件 - 显存占用
根据前文的表格数据可以得知:若需部署第二个模型,则即使对 70B 参数量模型采用最紧凑的 Q4_0 量化方案(显存占用最低配置),其仍会消耗约 43.1GB 显存空间。在双 RTX 3090 24G 显卡(总显存 48 GB)环境下,剩余仅剩不足 5GB 的显存可分配给其他模型。而对于可用级别的模型,最少也需要 5.5 GB 的显存才能加载,可能无法满足实际多任务并行需求。
软件条件 - 能跑
笔者认为目前在家用硬件上启动大语言模型,LM Studio 是比较好的选择。其适配的后台是 llama.cpp,支持 CUDA 和 ROCm 硬件。对于完全使用 GPU 运行的模型来讲,速度都不慢。此节省略更多技术细节,交由读者自行尝试。
选择模型
在备选的过程中考虑了一个 30B 的模型(qwq-32b)和一个 70B 的模型(llama-3-70B-it)。这两个模型都能在我的硬件中运行,其中较大参数量的模型在单独对话的过程中确实有较好的表现。因为推理模型需要等待更多的时间才能真正输出有效内容,因此基础模型这一点在体验上是优于需要等待的推理模型的。
笔者最终决定使用 QWQ-32B 推理模型作为主模型使用。此模型能提供大约 DeepSeek-R1 的能力,且占用合理资源,能够有更多的扩展空间。同时,此模型支持工具调用。
此配置大约使用 35 GB 显存,剩余 13 GB 显存供其他模型使用。
Gemma-3 目前不支持多轮对话角色混用,因此在浮望中不能用作辅助模型。否则,辅助模型和视觉辅助模型可以同时使用 Gemma-3。
2025.05.31 更新
在经过一些测试和调整以后,笔者通过覆盖 gemma-3-27b-int4-qat 的 Jinja 模版,为模型启用了视觉和工具调用双重支持。此模型质量非常高,不再使用其他任何模型。修改后的模版请参考文章末尾。
- 上下文长度(Context Length):100K
- GPU 装载(Offload):全部
- CPU Thread Pool:最大/16
- 批处理大小(Batch Size):16K
- 种子:-1 (随机)
- 闪电注意力(Flash Attention):启用
- K 量化:Q4_0
- V 量化:Q4_0
效果展示
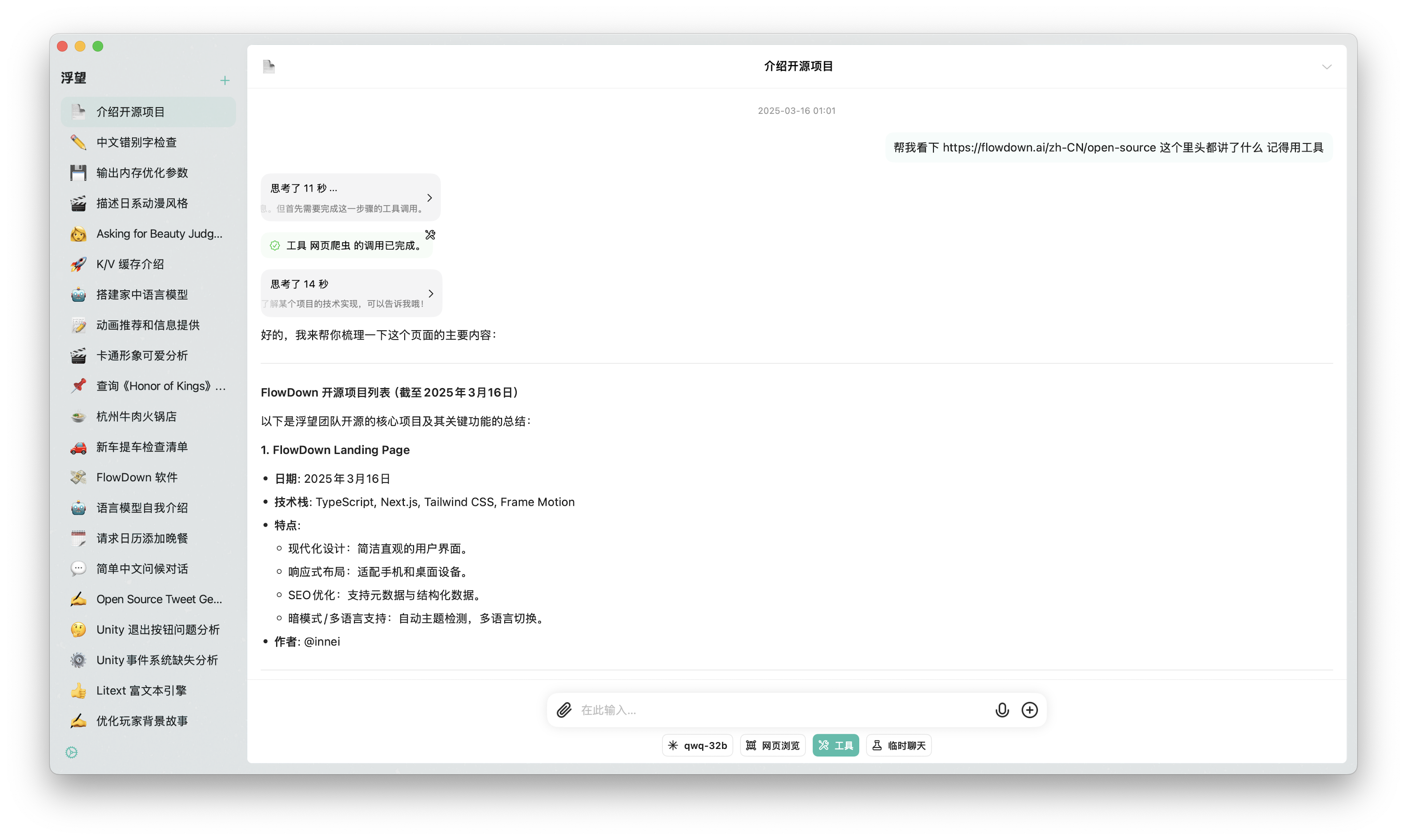
网络搜索
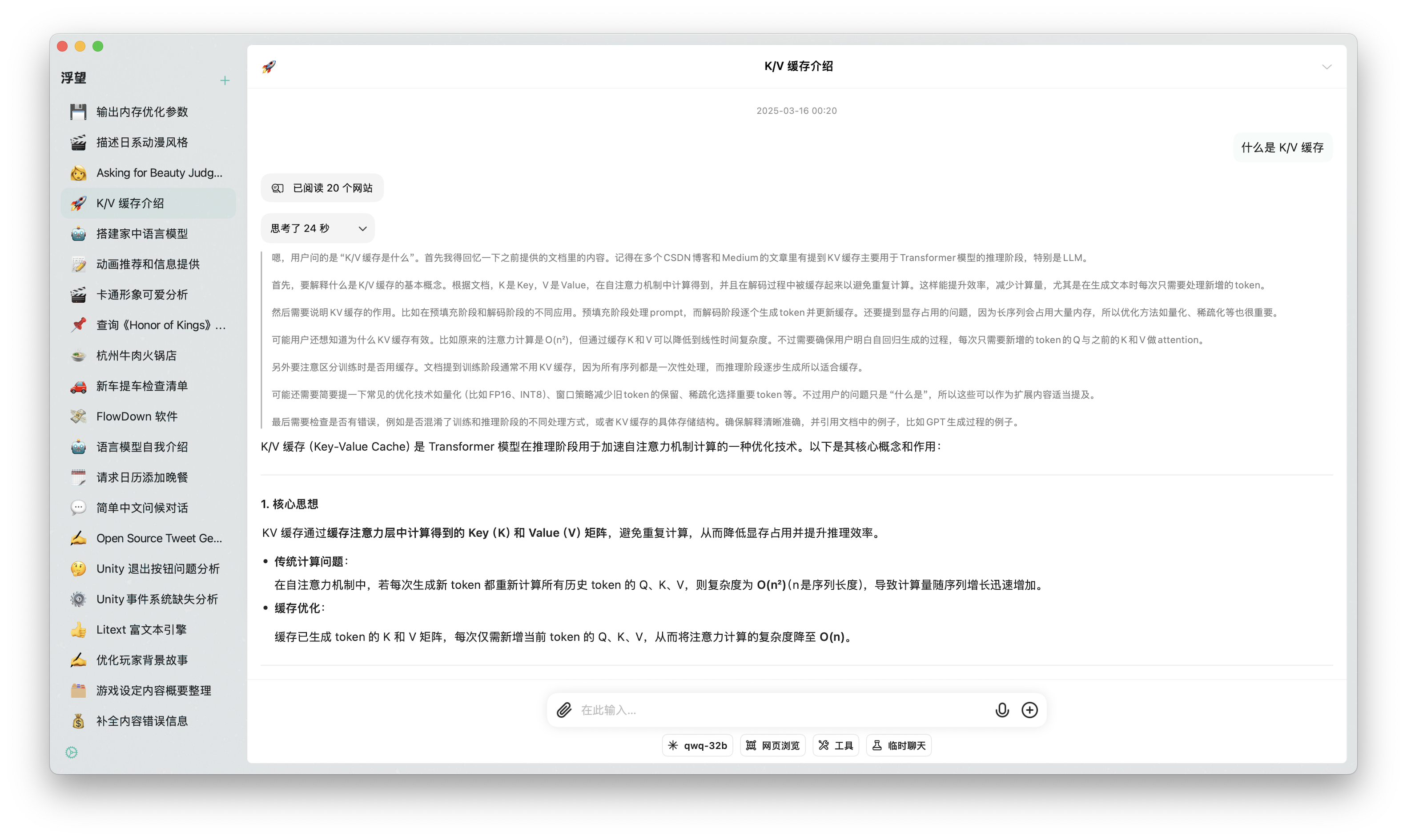
图片识别
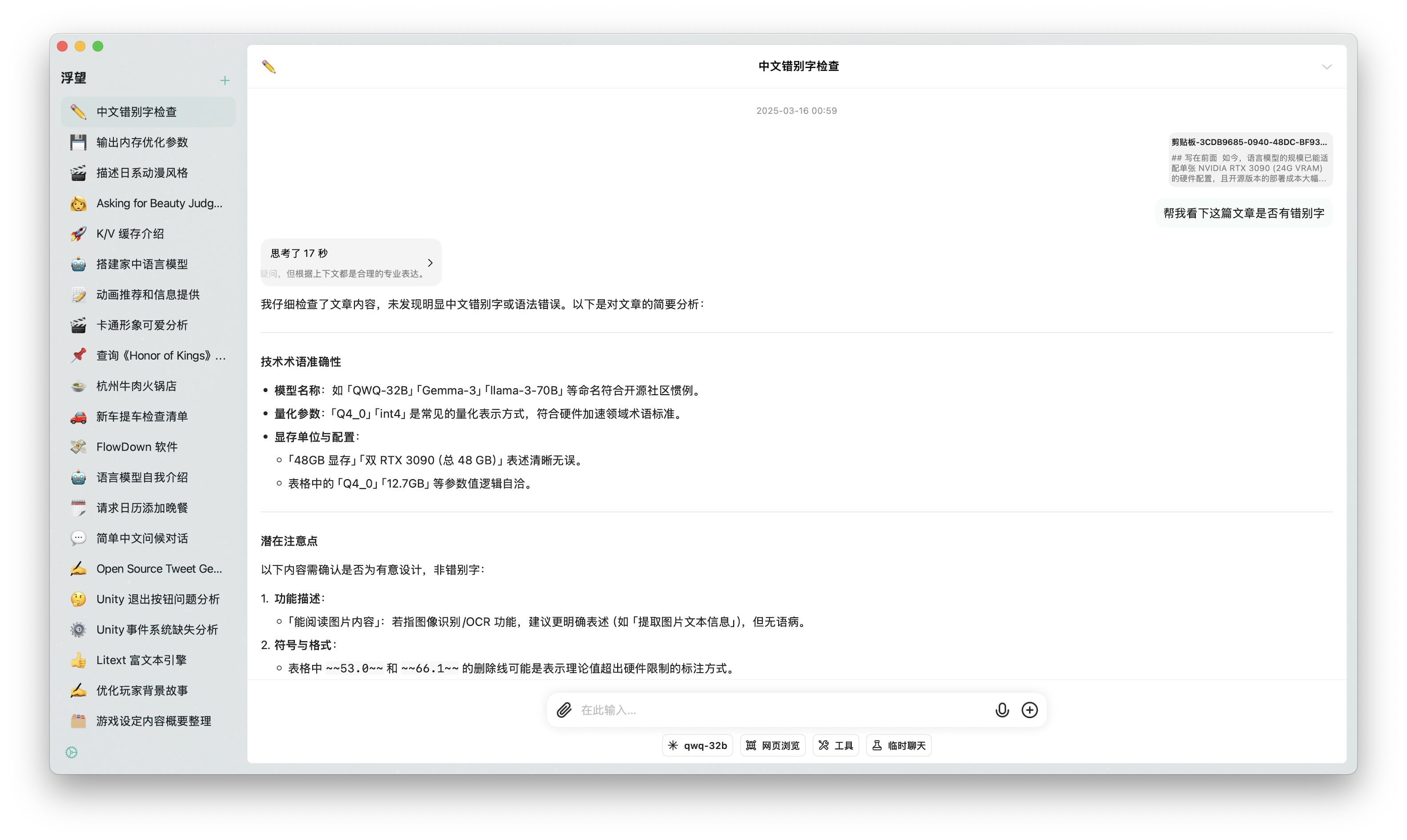
文档处理
工具调用
写在最后
本地部署大语言模型并非复杂的技术魔术。在云服务不断入侵个人生活的当下,用户数据是值得保护的。
你和朋友们的聊天是保密的,你和模型的聊天也应当是保密的。
而数据上云,无法做到可验证的隐私。
为此,笔者撰写了浮望,一款可以验证隐私保护的语言模型聊天软件。我的使命是为每一个人找回自己数字生活的所有权,浮望也是这样诞生的。
最后,请不必将硬件视为探索上限。无论是单显卡 16 GB 的配置或更精简环境,在开源社区与量化优化的加持下总存在适合的方案。你可以大胆选择尝试被笔者归为不可用的模型,调整上下文长度来适应你的需求。可以预见,在不久的将来,更小的模型将提供更好的性能,几倍的优化或者几百倍的质变都有可能发生。你应该自行探索。
若你已读至此,不妨动手试试。
额外内容:修改后的 Jinja 模版
{{ bos_token }}
{%- if messages[0]['role'] == 'system' -%}
{%- if messages[0]['content'] is string -%}
{%- set first_user_prefix = messages[0]['content'] + '\n\n' -%}
{%- else -%}
{%- set first_user_prefix = messages[0]['content'][0]['text'] + '\n\n' -%}
{%- endif -%}
{%- set loop_messages = messages[1:] -%}
{%- else -%}
{%- set first_user_prefix = "" -%}
{%- set loop_messages = messages -%}
{%- endif -%}
{%- if not tools is defined %}
{%- set tools = none %}
{%- endif %}
{%- for message in loop_messages -%}
{%- if (message['role'] == 'assistant') -%}
{%- set role = "model" -%}
{%- elif (message['role'] == 'tool') -%}
{%- set role = "user" -%}
{%- else -%}
{%- set role = message['role'] -%}
{%- endif -%}
{{ '<start_of_turn>' + role + '\n' -}}
{%- if loop.first -%}
{{ first_user_prefix }}
{%- if tools is not none -%}
{{- "You have access to the following tools to help respond to the user. To call tools, please respond with a python list of the calls. DO NOT USE MARKDOWN SYNTAX.\n" }}
{{- 'Respond in the format [func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)] \n' }}
{{- "Do not use variables.\n\n" }}
{%- for t in tools -%}
{{- t | tojson(indent=4) }}
{{- "\n\n" }}
{%- endfor -%}
{%- endif -%}
{%- endif -%}
{%- if 'tool_calls' in message -%}
{{- '[' -}}
{%- for tool_call in message.tool_calls -%}
{%- if tool_call.function is defined -%}
{%- set tool_call = tool_call.function -%}
{%- endif -%}
{{- tool_call.name + '(' -}}
{%- for param in tool_call.arguments -%}
{{- param + '=' -}}
{{- "%sr" | format(tool_call.arguments[param]) -}}
{%- if not loop.last -%}, {% endif -%}
{%- endfor -%}
{{- ')' -}}
{%- if not loop.last -%},{%- endif -%}
{%- endfor -%}
{{- ']' -}}
{%- endif -%}
{%- if (message['role'] == 'tool') -%}
{{ '<tool_response>\n' -}}
{%- endif -%}
{%- if message['content'] is string -%}
{{ message['content'] | trim }}
{%- elif message['content'] is iterable -%}
{%- for item in message['content'] -%}
{%- if item['type'] == 'image' -%}
{{ '<start_of_image>' }}
{%- elif item['type'] == 'text' -%}
{{ item['text'] | trim }}
{%- endif -%}
{%- endfor -%}
{%- else -%}
{{ raise_exception("Invalid content type") }}
{%- endif -%}
{%- if (message['role'] == 'tool') -%}
{{ '</tool_response>' -}}
{%- endif -%}
{{ '<end_of_turn>\n' }}
{%- endfor -%}
{%- if add_generation_prompt -%}
{{'<start_of_turn>model\n'}}
{%- endif -%}