获取本地模型
您可以直接在您的本地设备上直接运行模型,并进行模型推理,而不不是通过网络请求。
本地运行模型有以下几个优势:
- 隐私保障:所有数据在本地处理,不会上传到外部服务器
- 离线使用:无需网络连接也能使用模型功能
- 低延迟:无需等待网络传输,响应更快速
- 无额外费用:不需要支付API调用费用
- 完全控制:可以自由选择和定制模型
由于本地模型消耗的资源较大,本地模型有很大概率在 iPhone 上无法运行。因此我们仅推荐在 Mac 和配备了 Apple Silicon 的 iPad 上使用本地模型推理。
使用本地模型需要处理器支持。通常来讲,你需要使用装有 Apple Silicon 的设备。
所支持的模型种类
请务必设置中相应地启用视觉模式,以便使用相应的模型引擎。错误的配置可能会导致模型无法加载。
目前支持的本地文本模型类型有:
- Cohere
- Gemma
- Gemma2
- Gemma3
- InternLM2
- Llama / Mistral
- OpenELM
- Phi
- Phi3
- PhiMoE
- Qwen2
- Qwen3
- Starcoder2
- MiMo
- GLM4
目前支持的本地视觉文本模型类型有:
- Gemma3
从抱抱脸下载
在设置的模型管理页中,点击右上角的 加号 按钮,在菜单的 本地模型 中选择 从抱抱脸下载。
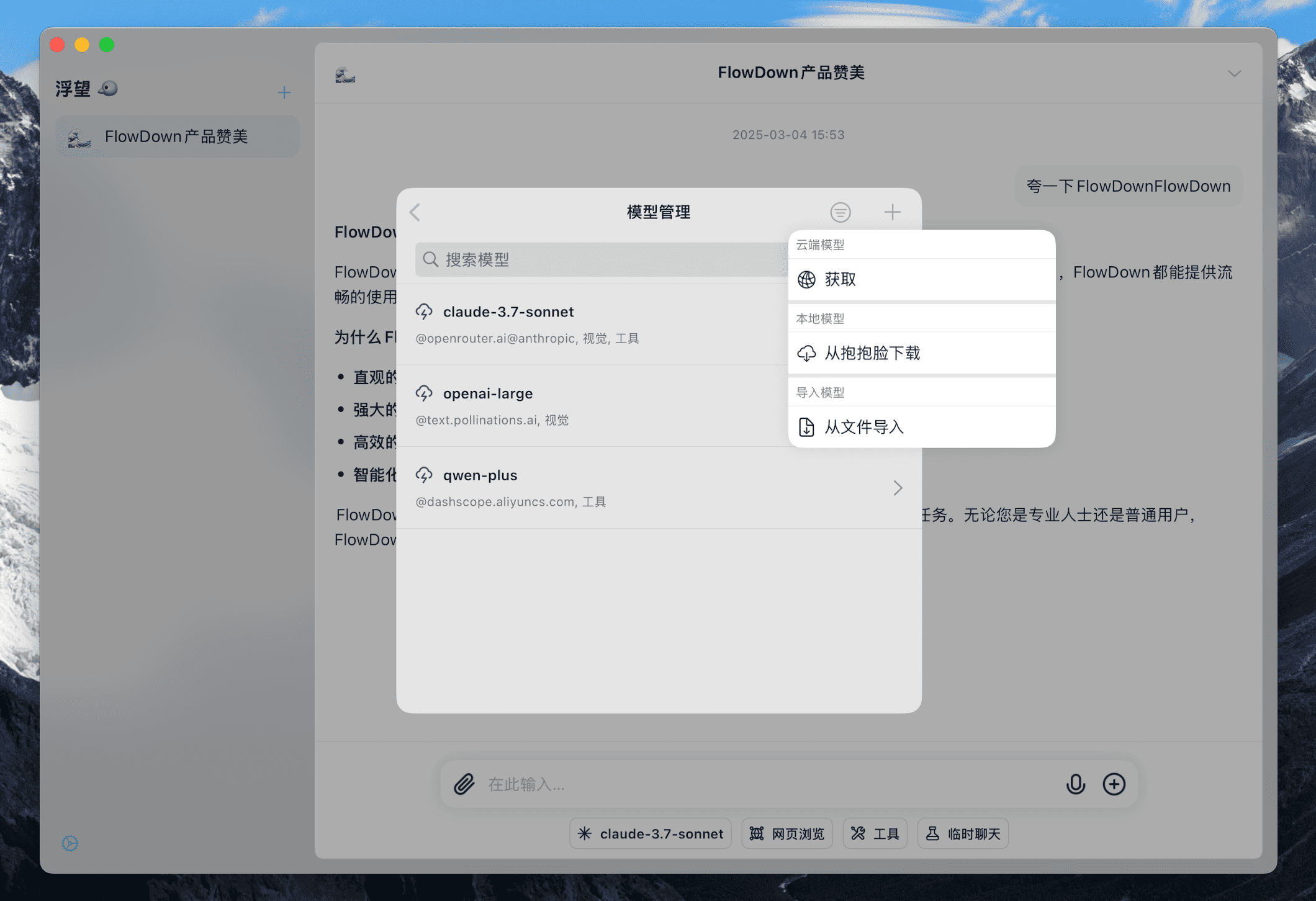
短暂等待后,将会看到从抱抱脸中获取的到模型列表。

还可以点击右上角的 更多 按钮对模型进行筛选。
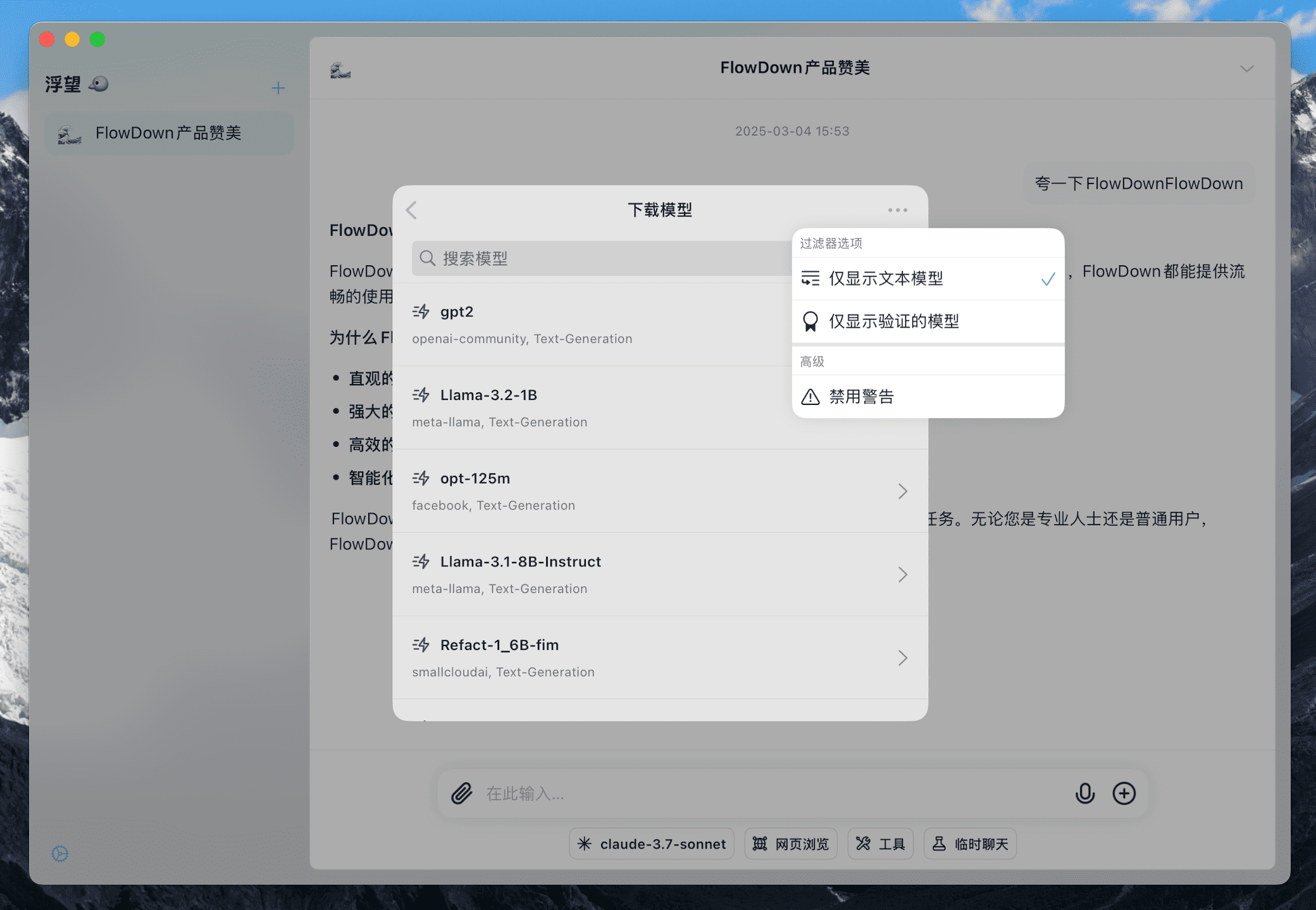
你可以点击任意模型查看模型的详细信息。
您需要自行判断模型是否能在您的设备上运行。
当您选择了一个无法运行的模型时,您可能会遇到因内存不足或其他原因导致的错误。
当您确保模型在您的设备上可用后,可在模型详情页点击右上角 下载 按钮下载模型。
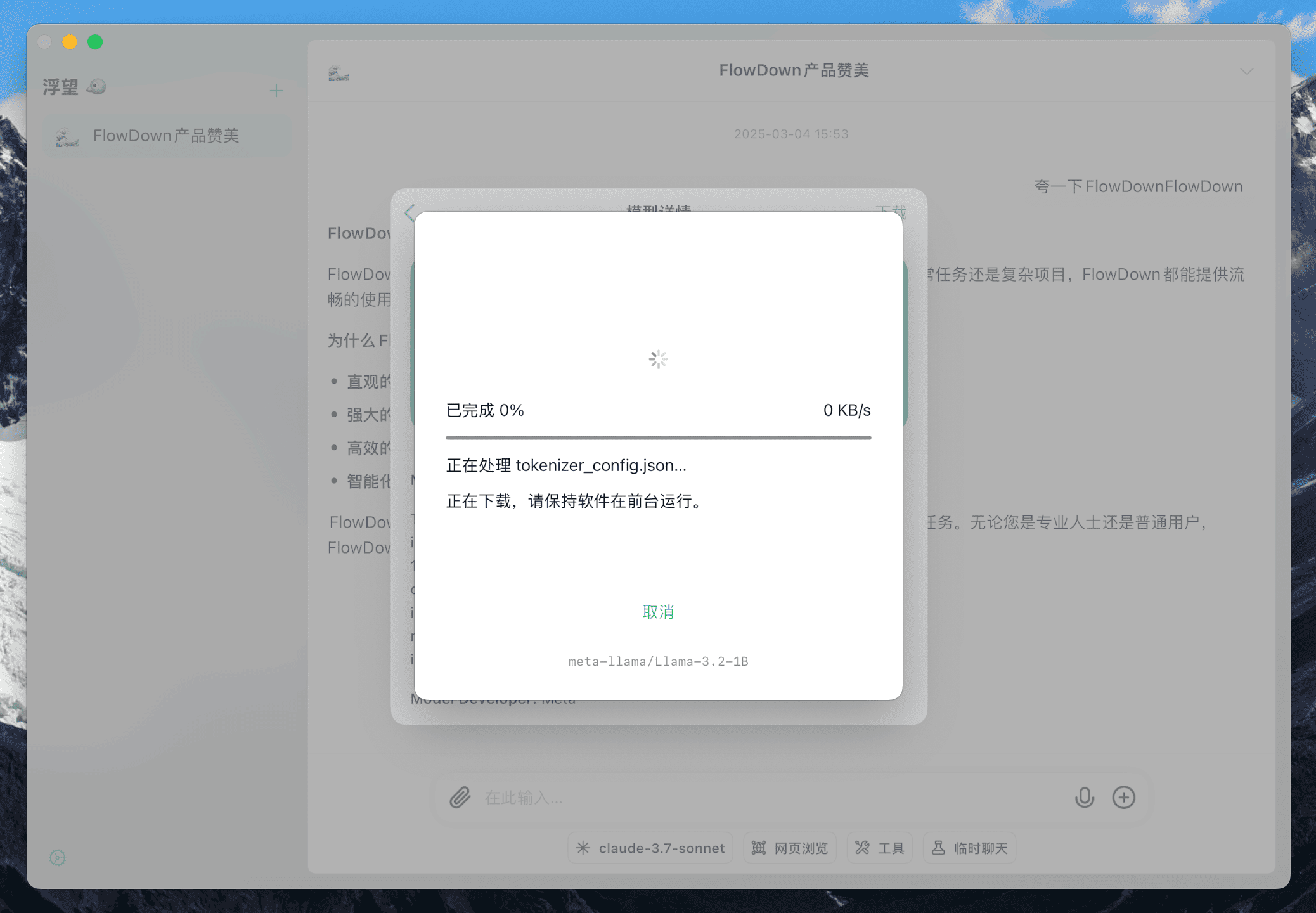
本地模型的体积较大,下载时间可能会比较长,请耐心等待模型下载完成。如果您下载的模型过大,我们认为您大概率无法运行该模型,您将会收到警告信息。

从本地导入
您可以选择自行下载模型并从本地导入。您需要准备一个压缩包,其中包含模型所需的配置和权重文件。
完成后,您可以在模型管理页中选择 从文件导入 来导入模型。
注意事项
- MLX 模型并非全部都可以加载。请参考 MLX-Swift 项目来获取列表。