模型配置 - 视觉
概述
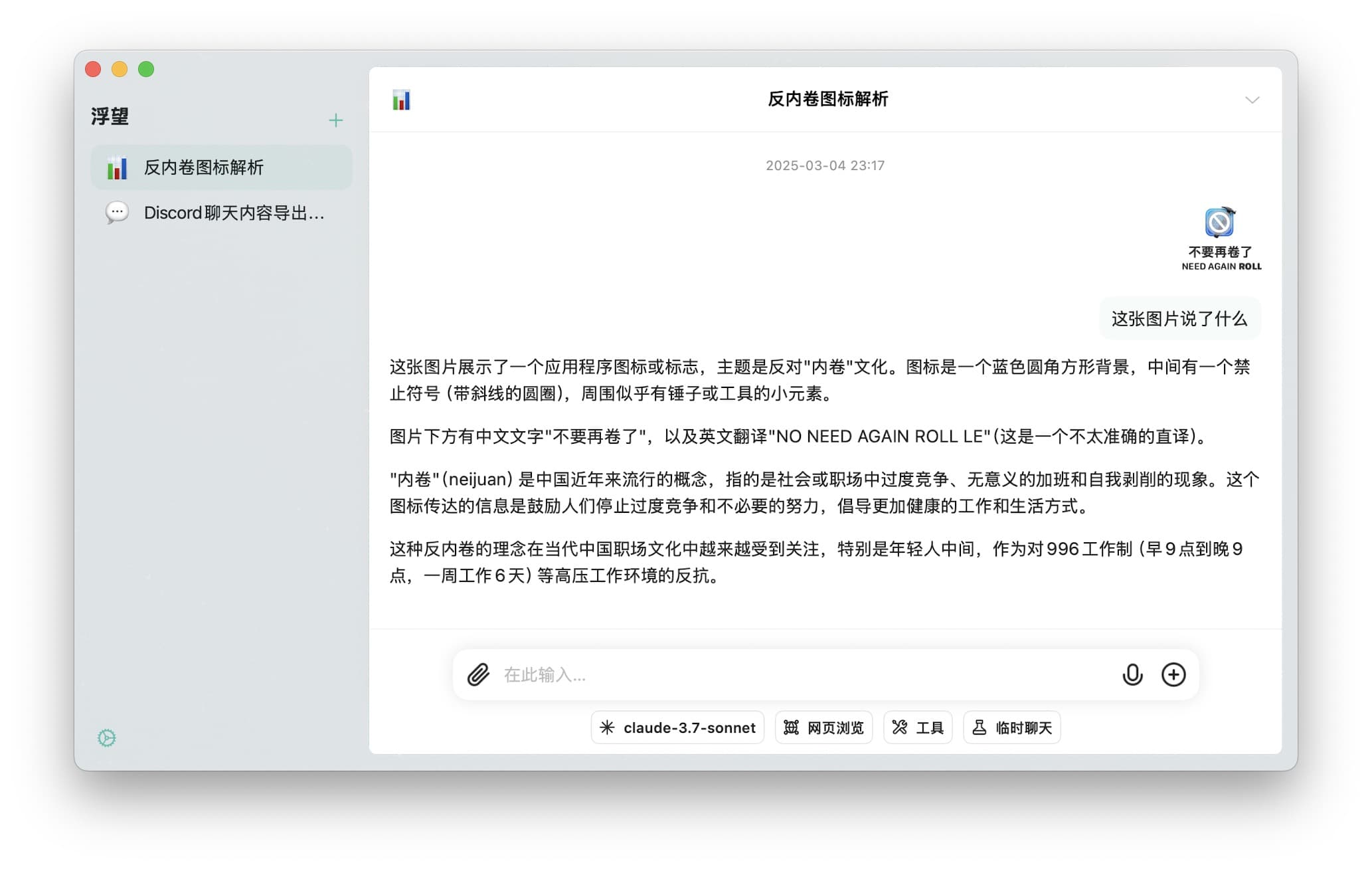
图像理解功能为浮望赋予了“视觉能力”,让它能看懂您分享的图片。
使用
简单三步操作:
- 对话界面点击"+"按钮上传图片
- 输入相关问题或指令
- 获取模型分析结果
您也可以直接拖拽图片到输入框,或使用粘贴功能快速添加图片。
配置
模型设置方式:
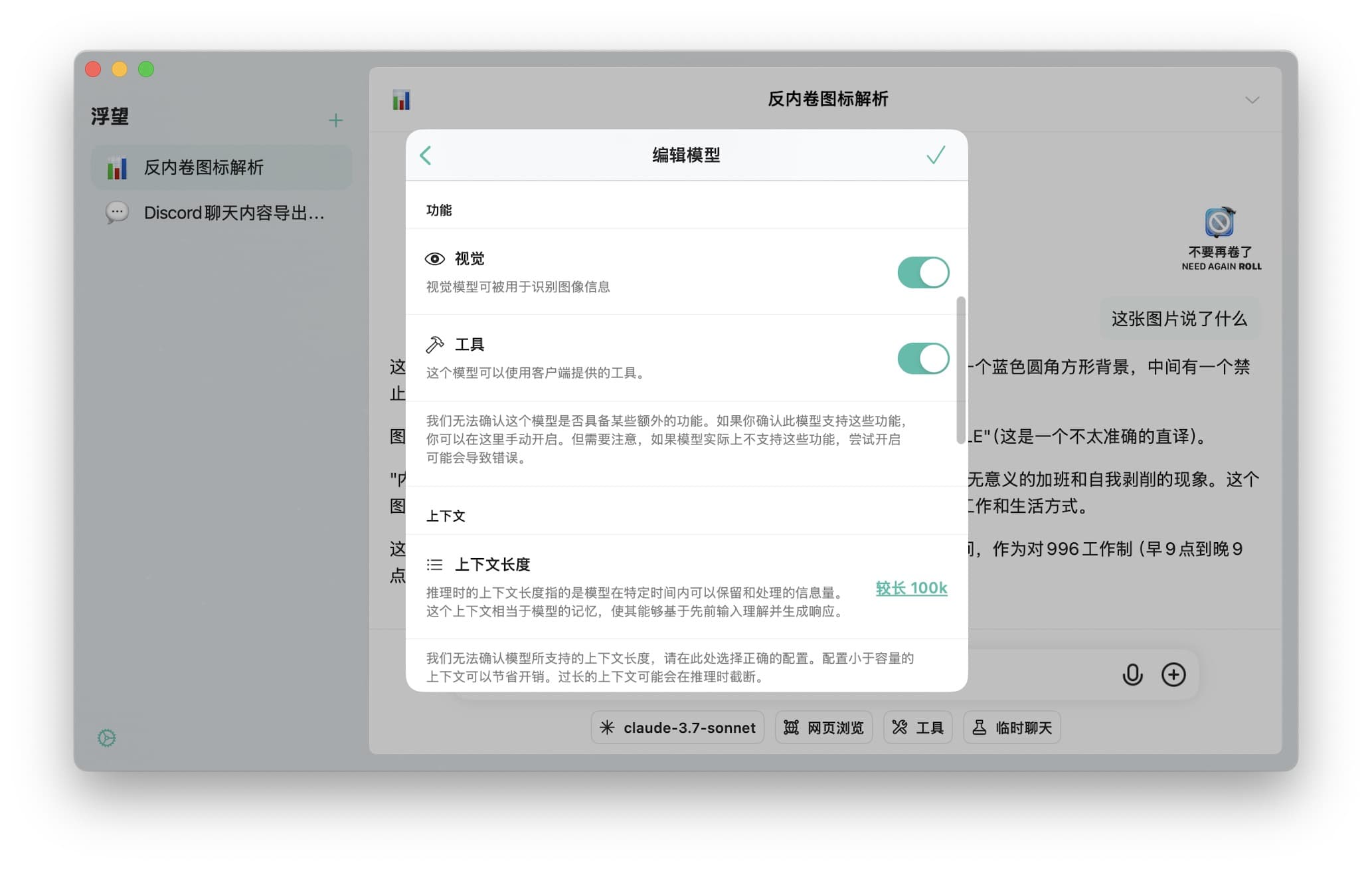
- 本地模型:设置 → 模型 → 选择目标模型 → 能力选项中启用"视觉"
- 云端模型:在模型编辑页面的能力部分开启"视觉"选项
注意:若本地模型支持视觉但未启用此选项,可能导致模型加载失败。不支持视觉的模型强行启用此功能可能引发错误。
预处理机制
预处理流程
- 通用信息提取:识别图像主要内容和元素
- 文字识别(OCR):提取图像中的文本
- 二维码解析:自动识别并处理图像中的二维码
模型选择机制
- 优先使用配置了视觉支持的任务模型
- 若无任务模型,则使用视觉备用模型
注意事项
- 当前对话模型不参与预处理。
- 图像中的扩展数据字段信息(EXIF)会被清除,包括拍摄时间、地点等。
完成对话
预处理完成后,系统会:
- 将提取的文本信息添加到对话上下文
- 若主对话模型支持视觉,原始图像也会添加到上下文中
建议
- 选择专业模型:云端大参数量的视觉模型提供更准确的图像理解
- 启用图像压缩:在通用设置中开启图像压缩,减少传输时间和流量
- 分步提问:在确认模型已经理解图像内容后,再提出相关问题
合理配置与使用图像分析功能,浮望可高效处理从物体识别到图表分析、文档解读等多样化图像任务。