Language Model Setup Guide @ Home Edition
The following content is automatically translated by LLM. If there are any errors, please refer to the original version or contact me.
This article's Chinese title is "The Actually Useful Workers at My Home." Different from other articles that teach you how to run a model, this article focuses more on practical user experience. The models configured in this article have replaced ChatGPT and similar software in my home, and I have uninstalled them all.
Preface
Today, language models can be fitted to run on a single NVIDIA RTX 3090 (24G VRAM), and the deployment cost of open-source versions has decreased significantly. For ordinary home users, this represents both a trend of technology accessibility and an excellent opportunity to explore reducing barriers to AI applications.
My purpose in writing this guide is to share some practical experiences of running language models at home. It is not intended to replace commercial large models (such as paid services), but rather to serve unique roles in specific scenarios—particularly those emphasizing privacy protection, such as assisting with confidential content for logical reasoning and thought expansion.
The inference configuration discussed here requires approximately 48GB of VRAM (dual RTX 3090 24G) and some RAM to run three models. This model combination offers text performance comparable to DeepSeek R1 level, meeting both lightweight basic task requirements and supporting all functions of my self-developed software "FlowDown". Due to time and resource constraints, I won't provide additional configuration options, but readers can use this as a starting point for their own exploration.
If you're interested in the design and technical implementation of FlowDown, you can refer to our documentation: https://FlowDown.ai/
Requirements
The motivation behind configuring these models was primarily need-driven, along with interest in cutting-edge technology. I wanted models that could:
- Provide decent text processing capabilities
- Organize complex information from the internet → handle longer context
- Offer some basic image processing capabilities → read image content
- Provide some simple code
- Meet all the functions of my self-developed software "FlowDown" → conversation title generation, image recognition, tool calling
- Fast inference speed → need immediate responses → must run on GPU
Capabilities
Based on these requirements, I explored the relationship between model size and capabilities about six months ago, dividing them into four levels. This section can be used as a direct reference—models that can run on home hardware are typically smaller than 70B and require some degree of quantization. The bolded content below indicates what can run on home hardware and provide practical utility.
- Unusable level: <7B, typical model: llama-1B
- Usable for simple tasks: 7B - 30B, typical model: Qwen 2.5 7B
- Usable for basic tasks: 30B-80B, typical models: Gemma-3-27B, QWQ-32B, llama-3-70B
- Fully usable: 80B+, typical models: Command-A 110B, DeepSeek-V3, DeepSeek-R1 671B
My Setup
Here's my configuration list.
,.=:!!t3Z3z., root@LAKR-HEDT
:tt:::tt333EE3 --------------
Et:::ztt33EEE @Ee., .., OS: Windows Server 2025 Datacenter [64 bit]
;tt:::tt333EE7 ;EEEEEEttttt33# Host: ASRock Z690 Taichi Razer Edition
:Et:::zt333EEQ. SEEEEEttttt33QL Kernel: 10.0.26100.0
it::::tt333EEF @EEEEEEttttt33F Motherboard: ASRock Z690 Taichi Razer Edition
;3=*^```'*4EEV :EEEEEEttttt33@. Uptime: 9 days 11 hours 25 minutes
,.=::::it=., ` @EEEEEEtttz33QF Packages: 2 (choco)
;::::::::zt33) '4EEEtttji3P* Shell: PowerShell v5.1.26100.2161
:t::::::::tt33 :Z3z.. `` ,..g. Resolution: 1024x768
i::::::::zt33F AEEEtttt::::ztF Terminal: Windows Console
;:::::::::t33V ;EEEttttt::::t3 CPU: 13th Gen Intel(R) Core(TM) i9-13900K @ 2.995GHz
E::::::::zt33L @EEEtttt::::z3F GPU: NVIDIA GeForce RTX 3090
{3=*^```'*4E3) ;EEEtttt:::::tZ` GPU: NVIDIA GeForce RTX 3090
` :EEEEtttt::::z7 GPU: Intel(R) UHD Graphics 770
'VEzjt:;;z>*` GPU: Microsoft Remote Display Adapter
Memory: 34.8 GiB / 127.75 GiB (27%)
Disk (C:): 68 GiB / 931 GiB (7%)Resource Usage
Parameter Count
Parameter count typically directly reflects model performance. Models with larger parameter counts generally outperform contemporaneous models with smaller parameter counts.
Context Length
Context, simply put, is the model's memory—it's the component that, aside from model capability, most significantly impacts user experience during inference.
With the same resources, larger parameter counts don't necessarily provide better experiences; sometimes, longer context is more suitable for your task.
In simple terms, running a 70B model might produce better output in simple conversations, but the model will quickly forget previous interactions and cannot process web search results. Meanwhile, a 30B long-context model can not only extract key information but also provide decent basic conversation capabilities.
With 48G of VRAM, you can fit approximately one 70B int4 quantized model. However, using a model of this size leaves very little context processing capacity.
Quantization
Model quantization can be explained as: significantly compressing the VRAM space occupied by a model while minimizing performance loss. For models optimized for quantization, performance loss is typically small—around 20% or less if a specific figure is needed. For models not optimized for quantization, the process can damage the model, causing it to output gibberish like repeated text or invalid characters.
For models that are optimized for quantization or at least not damaged by it, subjectively speaking: int4 quantization is currently the smallest acceptable compression. It represents an 8 or 16-bit data unit with a 4-bit integer.
This article uses int4 as the minimum quantization scheme.
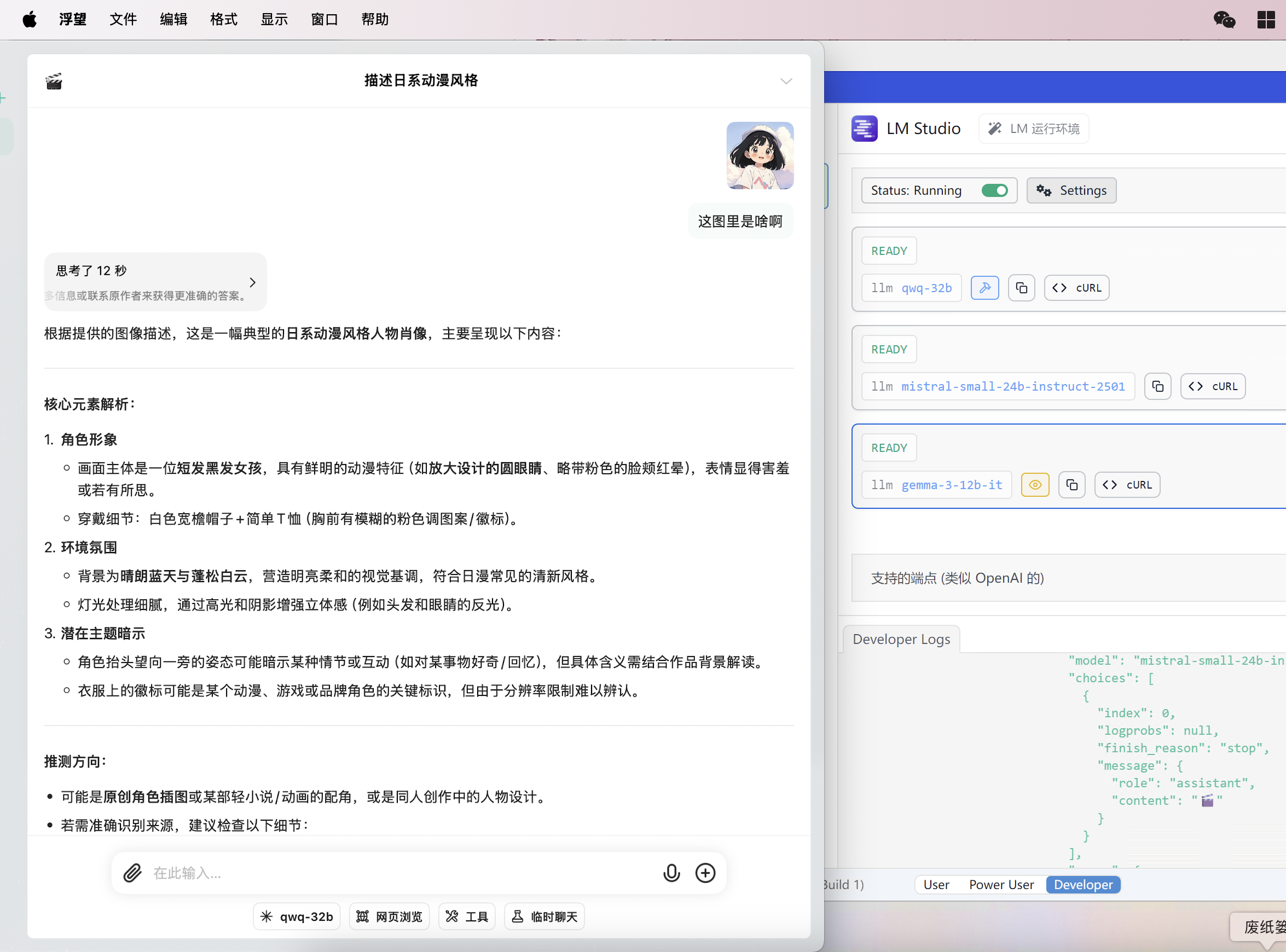
K/V Cache
Sufficient K/V cache must be allocated during model inference. The Key-Value Cache is an optimization technique used by Transformer models during inference to accelerate self-attention mechanism calculations.
You need to know: K/V cache can occupy significant storage space.
Preprocessing
The technical term for preprocessing is "Prefill," also known as "Pre Process," and sometimes abbreviated as "PP" in some forums.
In long-context inference processes, preprocessing speed is a particularly important metric. If it's too slow, it leads to unacceptably long wait times. Imagine completing a web search but having to wait two minutes before seeing the model's output—that's simply unacceptable. Many influencers purchase expensive hardware but overlook the importance of preprocessing and long context handling, which significantly impacts the overall model experience.
You need to know: Choosing devices that support CUDA for inference may significantly improve preprocessing speed.
If you're setting up your own home inference server based on this article, you should research this point when selecting hardware. Using devices optimized for this process can provide 100 to 1000 times speed improvement, significantly enhancing the user experience.
Reference Table
The table below clearly shows the hardware resources required under different quantization methods. You can use this website to calculate this: https://smcleod.net/vram-estimator/
| Parameters | Context Size | Quantization | Model Size (GB) | K/V Cache (GB) | Total VRAM Usage (GB) |
|---|---|---|---|---|---|
| 7B | 16K tokens | Q4_0 | 4.4 | 1.0 | 5.5 |
| 64K tokens | Q4_0 | 4.1 | 8.6 | ||
| 128K tokens | Q4_0 | 8.3 | 12.7 | ||
| 14B | 16K tokens | Q4_0 | 8.4 | 1.5 | 9.8 |
| 64K tokens | Q4_0 | 5.9 | 14.2 | ||
| 128K tokens | Q4_0 | 11.7 | 20.1 | ||
| 32B | 16K tokens | Q4_0 | 18.5 | 2.2 | 20.7 |
| 64K tokens | Q4_0 | 8.9 | 27.3 | ||
| 128K tokens | Q4_0 | 17.7 | 36.2 | ||
| 70B | 16K tokens | Q4_0 | 39.8 | 3.3 | 43.1 |
| 64K tokens | Q4_0 | 13.1 | |||
| 128K tokens | Q4_0 | 26.2 |
Model Selection
The base model directly determines daily user experience. In home hardware deployment scenarios, balancing model performance with resource consumption is the primary consideration. When performing inference on resource-constrained home devices, options for better model performance are limited.
Additionally, in small-parameter models, no single model can handle all functions. You need to modularly assemble different models to complete different tasks. Therefore, this article will explain the approach of using primary and secondary models along with visual assistant models.
Prerequisites
Hardware Requirements - VRAM Usage
Based on the table data above, we can see that: if you need to deploy a second model, even using the most compact Q4_0 quantization for a 70B parameter model (minimum VRAM configuration), it still consumes about 43.1GB of VRAM. In a dual RTX 3090 24G environment (total 48GB VRAM), less than 5GB remains for other models. For a usable model, at least 5.5GB of VRAM is needed, which may not meet actual multi-tasking requirements.
Software Requirements - Runnability
I believe that LM Studio is currently a good choice for running large language models on home hardware. It's compatible with llama.cpp backend and supports CUDA and ROCm hardware. For models running entirely on GPU, the speed is quite good. I'll omit more technical details in this section for readers to explore themselves.
Selecting the Model
During the selection process, I considered a 30B model (qwq-32b) and a 70B model (llama-3-70B-it). Both can run on my hardware, with the larger model showing better performance in individual conversations. Since inference models require more time to produce effective content, the base model provides a better experience than waiting for inference models.
I ultimately decided to use QWQ-32B reasoning model as my primary model. This model provides capabilities comparable to DeepSeek-R1, occupies reasonable resources, and allows more expansion space. Additionally, this model supports tool calling.
This configuration uses approximately 35GB of VRAM, leaving 13GB for other models.
Gemma-3 currently doesn't support multi-turn dialogues with mixed roles, so it can't be used as an assistant model in FlowDown. Otherwise, both the assistant and vision assistant models could use Gemma-3.
Updated May 31, 2025
After some testing and adjustments, I enabled dual support for vision and tool calling by overriding the Jinja template of gemma-3-27b-int4-qat. This model is of very high quality, and I no longer use any other models. Please refer to the modified template at the end of this article.
Actual running configuration:
- Context Length: 100K
- GPU Offload: Full
- CPU Thread Pool: Max/16
- Batch Size: 16K
- Seed: -1 (Random)
- Flash Attention: Enabled
- K Quantization: Q4_0
- V Quantization: Q4_0
Demonstrations
Web Search
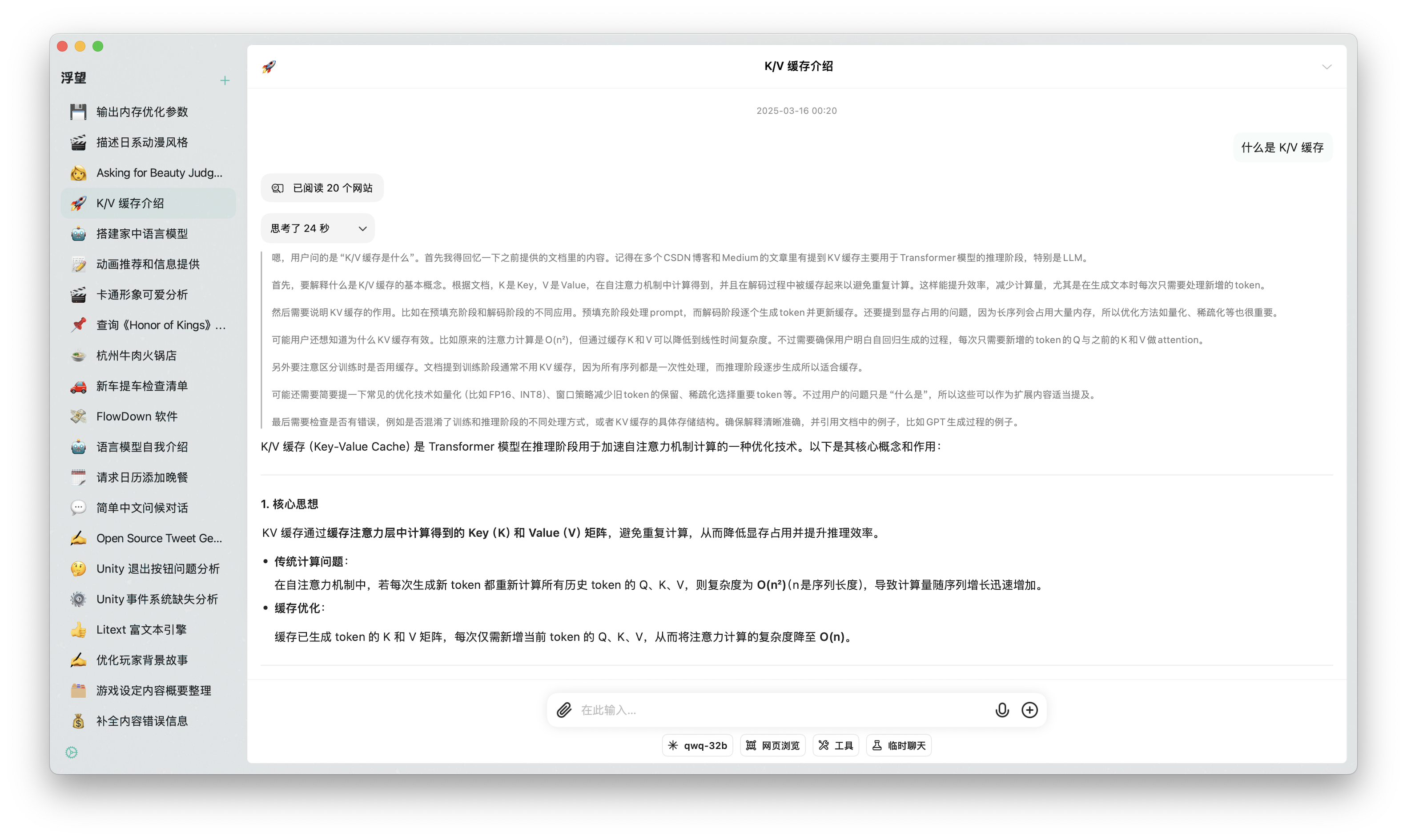
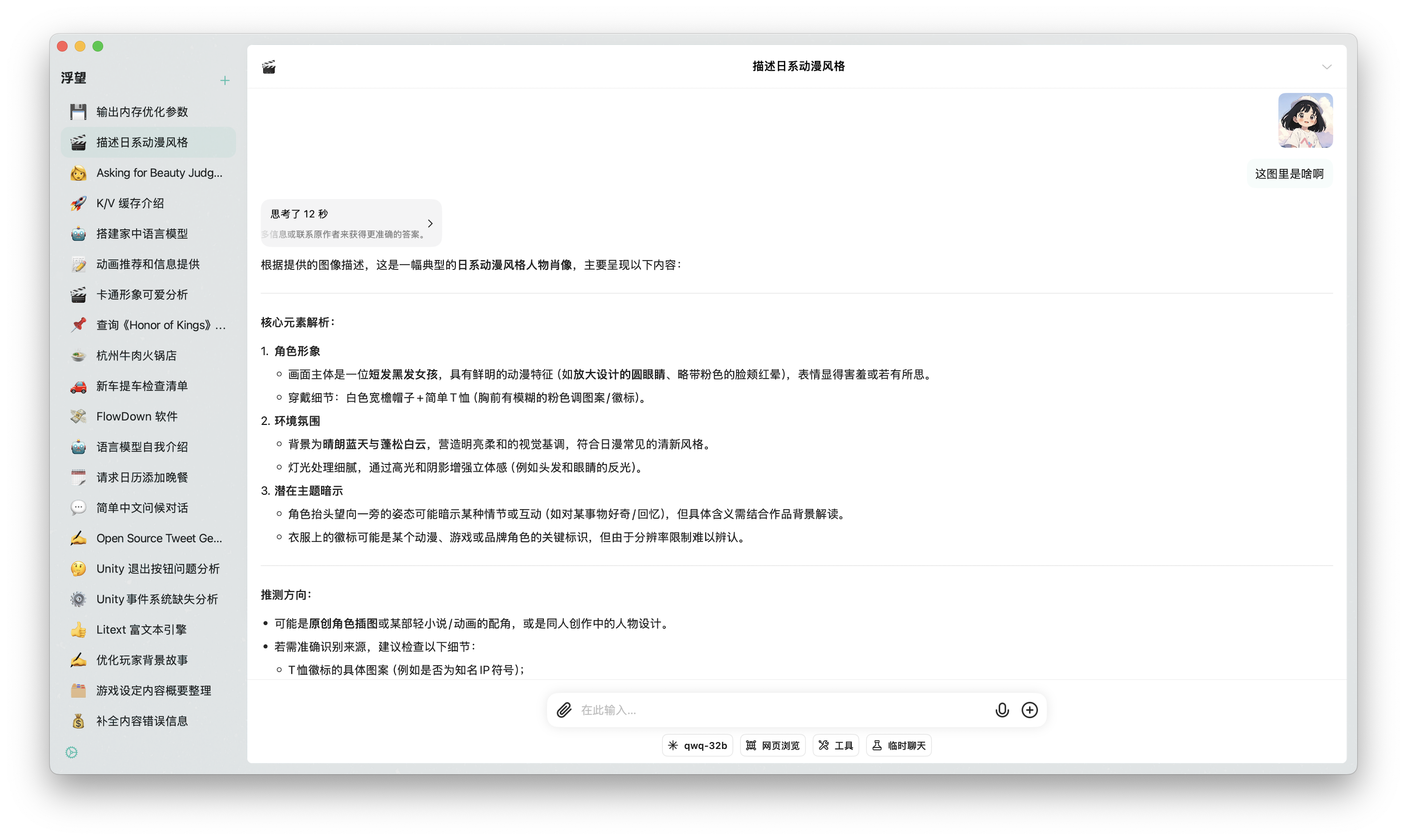
Image Recognition
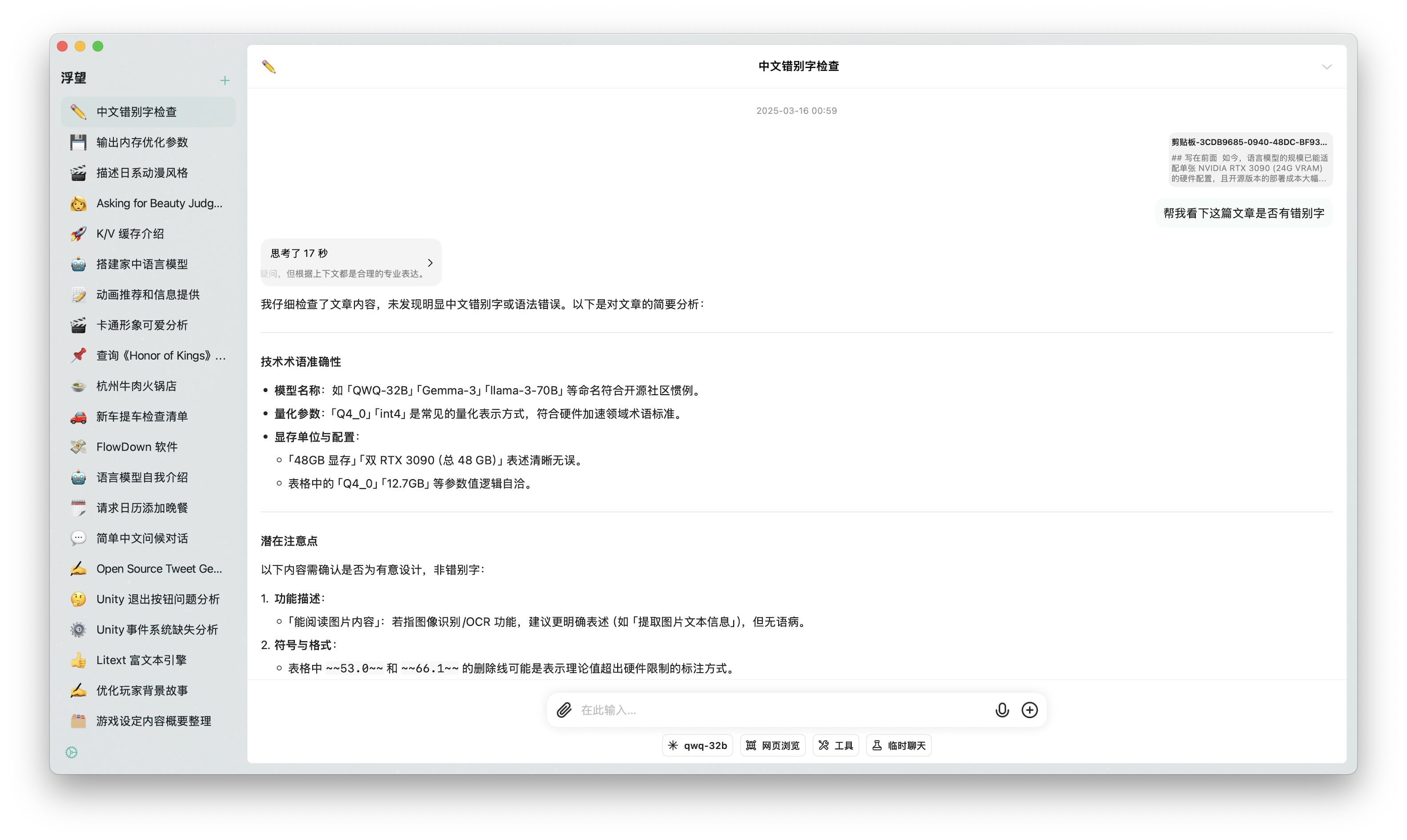
Document Processing
Tool Calling
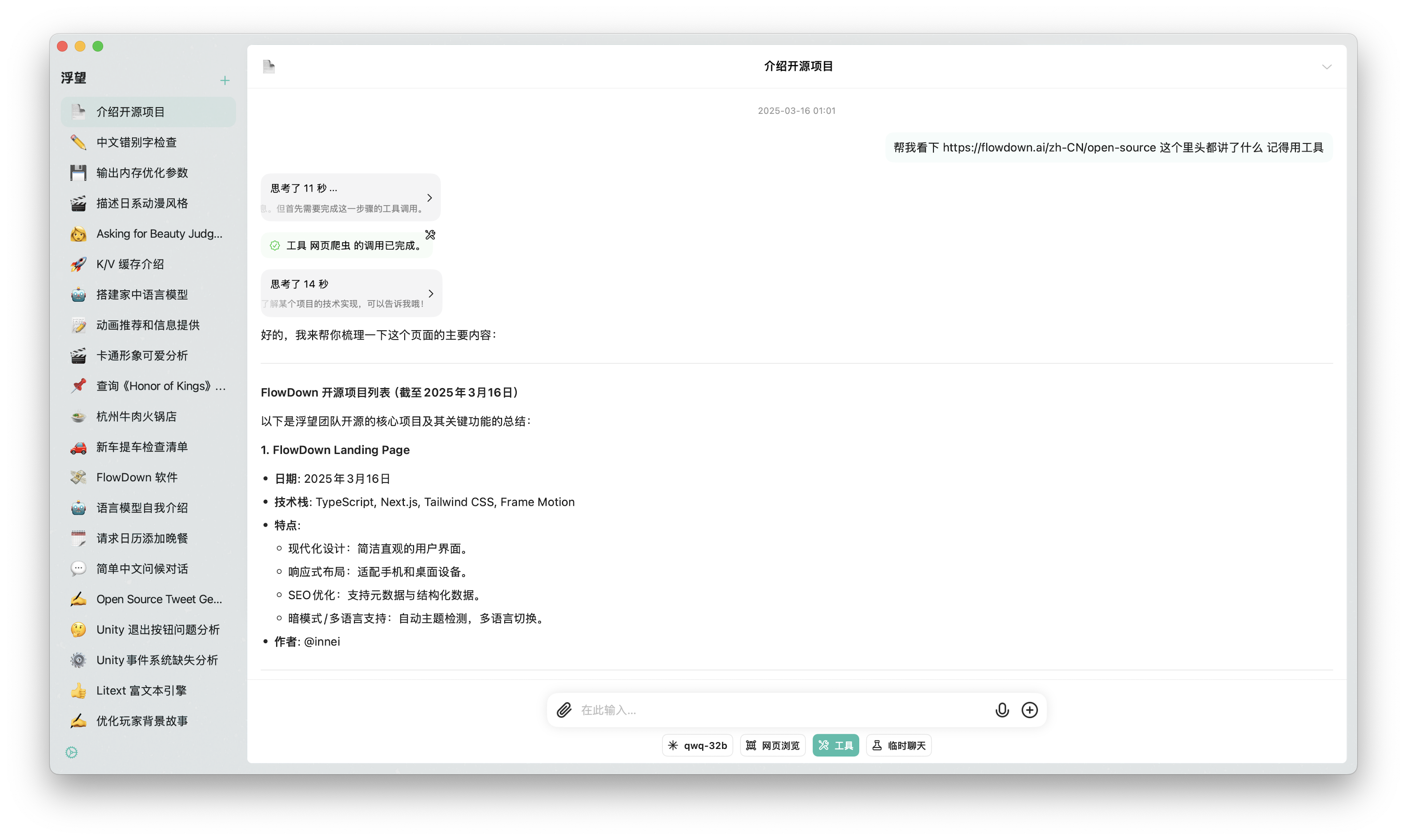
Conclusion
Deploying large language models locally isn't complex technical magic. In an era where cloud services increasingly invade personal lives, user data is worth protecting. Your chats with friends are confidential, and your conversations with models should be too. Cloud-based data cannot guarantee verifiable privacy.
For this reason, I developed FlowDown, a language model chat software with verifiable privacy protection. My mission is to help everyone reclaim ownership of their digital lives, which is how FlowDown came to be.
Finally, don't view hardware as an exploration ceiling. Whether using a single 16GB GPU or an even more streamlined environment, suitable solutions always exist thanks to the open-source community and quantization optimizations. Feel free to try models I've categorized as unusable, adjusting context length to suit your needs. In the near future, smaller models will likely provide better performance, with improvements of several times or even hundreds of times possible. You should explore on your own.
If you've read this far, why not give it a try?
Modified Jinja Template
{{ bos_token }}
{%- if messages[0]['role'] == 'system' -%}
{%- if messages[0]['content'] is string -%}
{%- set first_user_prefix = messages[0]['content'] + '\n\n' -%}
{%- else -%}
{%- set first_user_prefix = messages[0]['content'][0]['text'] + '\n\n' -%}
{%- endif -%}
{%- set loop_messages = messages[1:] -%}
{%- else -%}
{%- set first_user_prefix = "" -%}
{%- set loop_messages = messages -%}
{%- endif -%}
{%- if not tools is defined %}
{%- set tools = none %}
{%- endif %}
{%- for message in loop_messages -%}
{%- if (message['role'] == 'assistant') -%}
{%- set role = "model" -%}
{%- elif (message['role'] == 'tool') -%}
{%- set role = "user" -%}
{%- else -%}
{%- set role = message['role'] -%}
{%- endif -%}
{{ '<start_of_turn>' + role + '\n' -}}
{%- if loop.first -%}
{{ first_user_prefix }}
{%- if tools is not none -%}
{{- "You have access to the following tools to help respond to the user. To call tools, please respond with a python list of the calls. DO NOT USE MARKDOWN SYNTAX.\n" }}
{{- 'Respond in the format [func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)] \n' }}
{{- "Do not use variables.\n\n" }}
{%- for t in tools -%}
{{- t | tojson(indent=4) }}
{{- "\n\n" }}
{%- endfor -%}
{%- endif -%}
{%- endif -%}
{%- if 'tool_calls' in message -%}
{{- '[' -}}
{%- for tool_call in message.tool_calls -%}
{%- if tool_call.function is defined -%}
{%- set tool_call = tool_call.function -%}
{%- endif -%}
{{- tool_call.name + '(' -}}
{%- for param in tool_call.arguments -%}
{{- param + '=' -}}
{{- "%sr" | format(tool_call.arguments[param]) -}}
{%- if not loop.last -%}, {% endif -%}
{%- endfor -%}
{{- ')' -}}
{%- if not loop.last -%},{%- endif -%}
{%- endfor -%}
{{- ']' -}}
{%- endif -%}
{%- if (message['role'] == 'tool') -%}
{{ '<tool_response>\n' -}}
{%- endif -%}
{%- if message['content'] is string -%}
{{ message['content'] | trim }}
{%- elif message['content'] is iterable -%}
{%- for item in message['content'] -%}
{%- if item['type'] == 'image' -%}
{{ '<start_of_image>' }}
{%- elif item['type'] == 'text' -%}
{{ item['text'] | trim }}
{%- endif -%}
{%- endfor -%}
{%- else -%}
{{ raise_exception("Invalid content type") }}
{%- endif -%}
{%- if (message['role'] == 'tool') -%}
{{ '</tool_response>' -}}
{%- endif -%}
{{ '<end_of_turn>\n' }}
{%- endfor -%}
{%- if add_generation_prompt -%}
{{'<start_of_turn>model\n'}}
{%- endif -%}